Компания Apple представила комплексную стратегию интеграции языковых моделей в свою экосистему, фокусируясь на локальной обработке данных и включающую компактную модель для работы непосредственно на устройствах и более мощное серверное решение для обработки сложных задач.
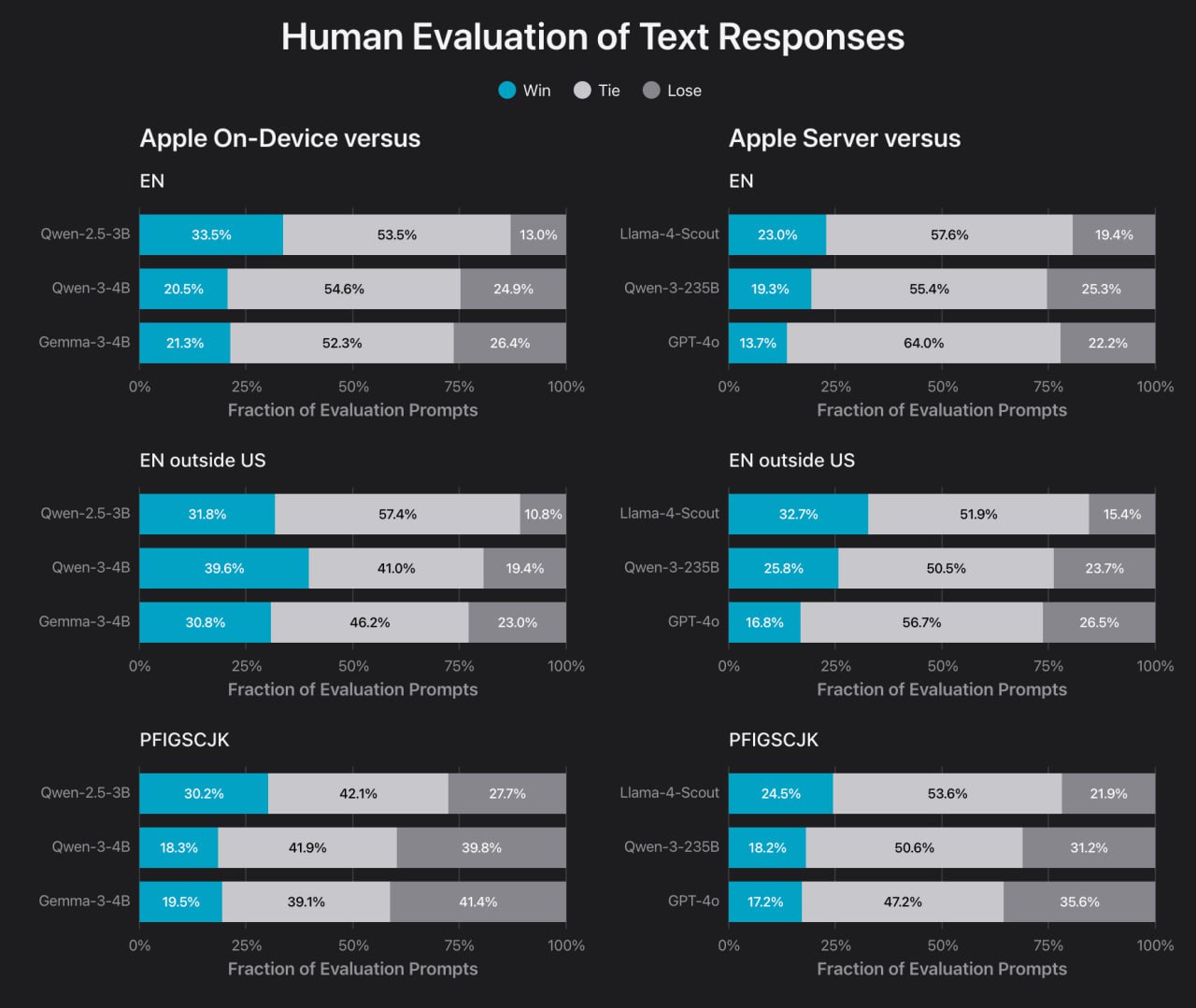
Локальная языковая модель Apple характеризуется архитектурой с 3 млрд параметров и оптимизирована для работы в условиях ограниченных вычислительных ресурсов мобильных устройств. По производительности она сопоставима с Qwen 2.5 4B, но уступает Google DeepMind Gemma 3 4B.
Технические специалисты Apple применили глубокую квантизацию для локальной модели, сократив объем данных до 2 бит на параметр, что существенно снижает требования к хранилищу и оперативной памяти.
Данный подход позволяет достичь скорости генерации 30 токенов в секунду на устройствах уровня iPhone 15 Pro, обеспечивая баланс между производительностью и энергопотреблением.
Серверная часть решения представляет собой ансамбль специализированных моделей, настроенных на различные типы задач. Архитектура включает отдельные нейронные сети для суммаризации, переписывания и других функций, что позволяет оптимизировать производительность для конкретных сценариев использования.
Несмотря на то, что серверное решение уступает по качеству GPT-4o, оно предлагает существенные преимущества в скорости работы, доступности и защите данных.
Технологическое решение также включает функциональность вызова функций (function calling), позволяющую моделям взаимодействовать с внешними системами и API, что расширяет спектр практических применений.
