Компания Scale AI представила новый инструмент оценки возможностей искусственного интеллекта в программировании - SWE-BENCH PRO. Бенчмарк показал, что даже самые мощные ИИ-модели способны решить менее четверти сложных задач разработки, максимально приближенных к реальным условиям.
Новый тест основан на популярном SWE-BENCH, но ориентирован на проверку ИИ-агентов в условиях, максимально близких к настоящей разработке программного обеспечения.
В набор вошли 1865 задач из 41 репозитория, разделенных на три категории: открытую (731 задача) из проектов со строгими лицензиями типа GPL, коммерческую (276 задач) из закрытых кодовых баз стартапов и закрытый поднабор (858 задач), который защищен от “подглядывания” при обучении моделей.
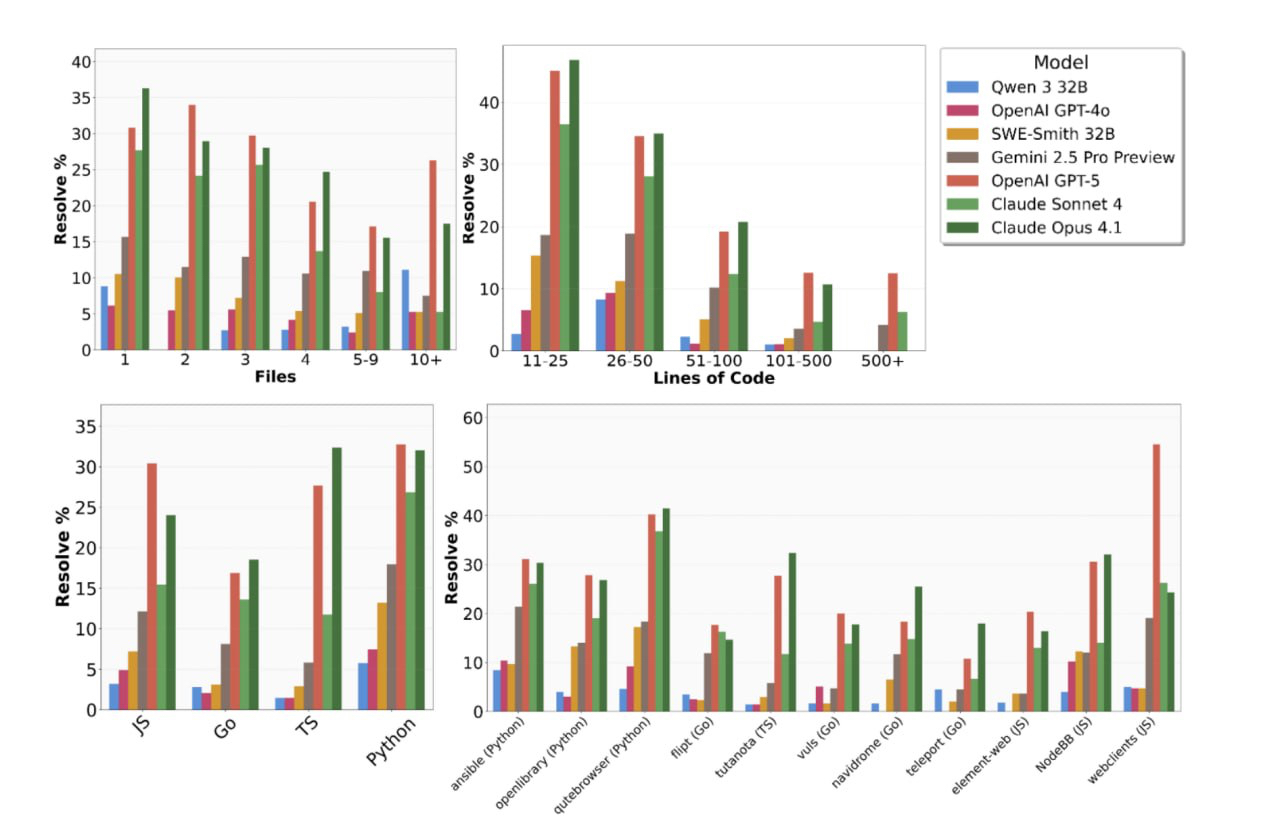
Главное отличие SWE-BENCH PRO от существующих тестов - значительно более высокий уровень сложности. В среднем решение требует изменения 107 строк кода в четырех различных файлах, а некоторые задачи включают редактирование нескольких сотен строк одновременно. Это гораздо ближе к реальным сценариям сопровождения и развития крупных программных проектов.
Для оценки всех моделей использовался единый агентный шаблон SWE-Agent с одинаковыми настройками. Основной метрикой стал процент задач, решенных с первой попытки (Pass@1). Каждая модель могла выполнить до 200 шагов на одну задачу. Результаты были зафиксированы по состоянию на 18 сентября 2025 года.
Даже лидеры рейтинга продемонстрировали весьма ограниченные результаты. На открытой части бенчмарка первое место занял GPT-5 с показателем 23,3%, а следом за ним идет Claude Opus 4.1 с результатом 22,7%. На коммерческой части теста лучший результат составил всего 17,8% (Claude Opus 4.1).
Исследование выявило заметные различия в эффективности ИИ для разных языков программирования. Наилучшие результаты модели показали при работе с Python и Go, а наибольшие трудности вызвали задачи на JavaScript и TypeScript.
Авторы исследования подчеркивают, что SWE-BENCH PRO наглядно демонстрирует критический разрыв между возможностями современных ИИ-систем и требованиями реальной разработки. Если на предыдущих, более простых тестах лучшие модели показывали успешность выше 70%, то новый бенчмарк фиксирует уровень всего в 18-23%.
