Гигантские языковые модели начинают уменьшаться в размерах. При этом их возможности продолжают расти. Что стоит за этим парадоксом, и почему крупнейшие AI-компании мира отказываются от гонки за количеством параметров? Давайте разберемся в деталях этого удивительного явления.
Эволюция в цифрах
История развития современных языковых моделей началась в 2017 году с появлением архитектуры трансформер. Первая модель семейства GPT содержала всего 117 миллионов параметров — по современным меркам это крошечная цифра.
Однако уже через 2 года мир увидел GPT-3 с поражающими воображение 175 миллиардами параметров — в тысячу раз больше предшественницы! Это событие стало настоящей революцией в мире AI и задало тренд на увеличение размера моделей.
Казалось, тенденция к увеличению будет только нарастать. GPT-4, выпущенная еще через три года, достигла невероятных 1.8 триллиона параметров — в десять раз больше GPT-3. На весенней конференции Microsoft даже демонстрировалась знаменитая иллюстрация с китом, намекающая на колоссальные размеры будущей GPT-5. Индустрия была уверена: чем больше параметров, тем умнее модель.
Если бы эта тенденция сохранилась, сегодня мы бы говорили о моделях с примерно 10 триллионами параметров. Однако реальность преподнесла сюрприз, который заставил переосмыслить базовые принципы развития искусственного интеллекта.
Неожиданный поворот
Вместо дальнейшего роста начался обратный процесс. По оценкам экспертов, GPT-4o имеет около 200 миллиардов параметров — в 8-10 раз меньше, чем GPT-4.
Claude 3.5 Sonnet, одна из самых продвинутых моделей на рынке, предположительно содержит около 400 миллиардов параметров.
И это не просто случайное отклонение от тренда, а новая реальность в мире AI.
Эти оценки подтверждаются несколькими способами. Во-первых, анализом открытых моделей: лучшие из них — Mistral Large 2 (123 миллиарда параметров) и Llama 3.3 70B (70 миллиардов параметров) — показывают производительность на уровне моделей предыдущего поколения, таких как оригинальная GPT-4 и Claude 3 Opus.
При этом они значительно компактнее и эффективнее в использовании.
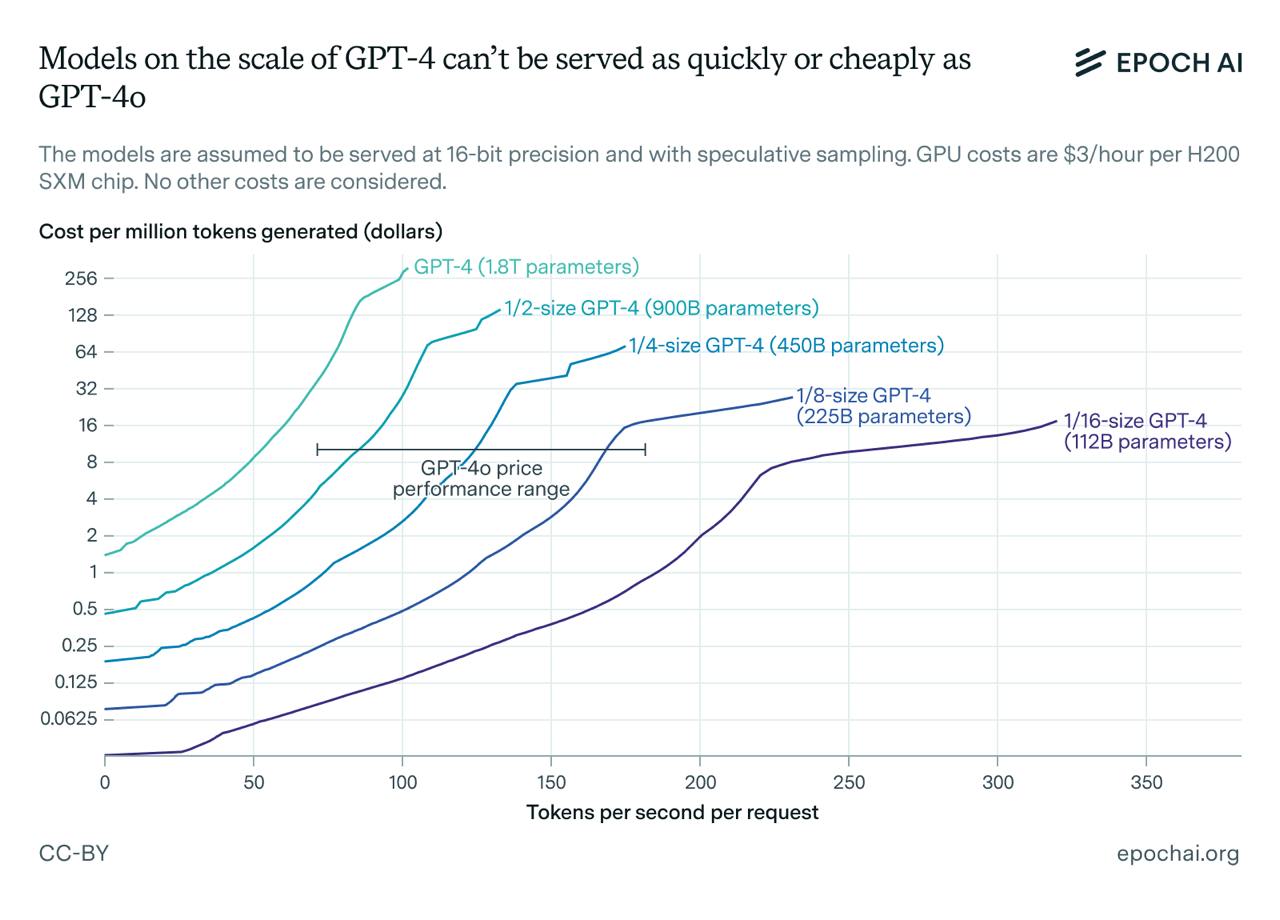
Во-вторых, о размере закрытых моделей можно судить по скорости обработки запросов и стоимости использования. Например, GPT-4o генерирует 100-150 токенов в секунду при цене $10 за миллион токенов.
Для сравнения, GPT-4 Turbo выдает максимум 55 токенов в секунду и стоит $30 за миллион токенов, а оригинальная GPT-4 обходится в $60 за миллион токенов. Эти цифры говорят сами за себя: меньшие модели работают быстрее и обходятся дешевле.
Причины перемен
Эксперты выделяют три ключевых фактора, объясняющих этот разворот тренда:
- Экономика масштаба. После выпуска ChatGPT в декабре 2022 года и GPT-4 в марте 2023 года спрос на AI-сервисы взлетел до небес. Компании столкнулись с необходимостью обрабатывать огромное количество запросов при разумных затратах.
Большие модели оказались слишком дорогими в обслуживании, и бизнес начал искать более эффективные решения.
- Синтетические данные. Современные технологии открыли новые возможности: теперь можно увеличивать сложность обучения без наращивания размера модели, используя искусственно созданные данные.
Это позволяет достигать лучших результатов при меньших затратах ресурсов.
- Новый закон масштабирования. До 2020 года считалось критически важным поддерживать высокое соотношение между количеством параметров и объемом обучающих данных. Однако в 2022 году группа исследователей во главе с Hoffmann представила новый принцип, получивший название “закон Чинчиллы”.
Оказалось, что вместо увеличения числа параметров лучшей производительности можно достичь, расширяя набор обучающих данных. Это открытие перевернуло представление о том, как следует развивать языковые модели.
Особенно интересно наблюдать за экономическими аспектами этих изменений. Используя теоретические модели экономики инференса, можно предсказать, насколько дешево может обслуживаться GPT-4 на современном оборудовании, например, на графических процессорах H200.
При условии операционных затрат в $3 в час на использование H200 для инференса, становится очевидным, почему компании стремятся к оптимизации размера моделей.
Что дальше
Несмотря на текущую тенденцию к уменьшению, эксперты не ожидают, что модели продолжат сокращаться такими же темпами. Для этого есть несколько важных причин:
-
Смена законов масштабирования была одноразовым эффектом, который уже в значительной степени реализован.
-
Существует естественный предел уменьшения размера модели при сохранении высокой производительности. Нельзя бесконечно сокращать количество параметров, не теряя в качестве работы.
-
Современные приоритеты включают test-time compute scaling, а развитие аппаратного обеспечения продолжается. Это открывает новые возможности для оптимизации работы моделей.
-
Большие модели сохраняют преимущество при работе с длинными цепочками рассуждений и обширным контекстом. Например, Claude 3.5 Sonnet демонстрирует стабильную скорость работы даже при обработке контекста длиной в 100 тысяч токенов.
Интересно отметить, что даже при относительно небольшом размере современные модели показывают впечатляющие результаты. Например, переход от Llama 2 70B к Llama 3 70B демонстрирует, как можно увеличивать вычислительную сложность обучения без увеличения размера модели.
На практике это означает, что индустрия нашла более эффективный баланс между размером моделей и их производительностью. Вместо бесконечного наращивания параметров компании сосредоточились на оптимизации архитектуры и более эффективном использовании данных для обучения.
