Масштабное исследование показало, что увеличение вычислительных ресурсов во время работы ИИ не гарантирует улучшения результатов, как считалось ранее. В беспрецедентном по масштабу исследовании команда Microsoft проанализировала работу девяти передовых моделей искусственного интеллекта.
Включая такие флагманы индустрии, как GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Pro и Llama 3.1 405B. Особое внимание было уделено моделям, специально настроенным на улучшенные рассуждения: OpenAI o1 и o3-mini, Anthropic Claude 3.7 Sonnet, Google Gemini 2 Flash Thinking и DeepSeek R1.
Узнать подробнее про клуб ShareAI
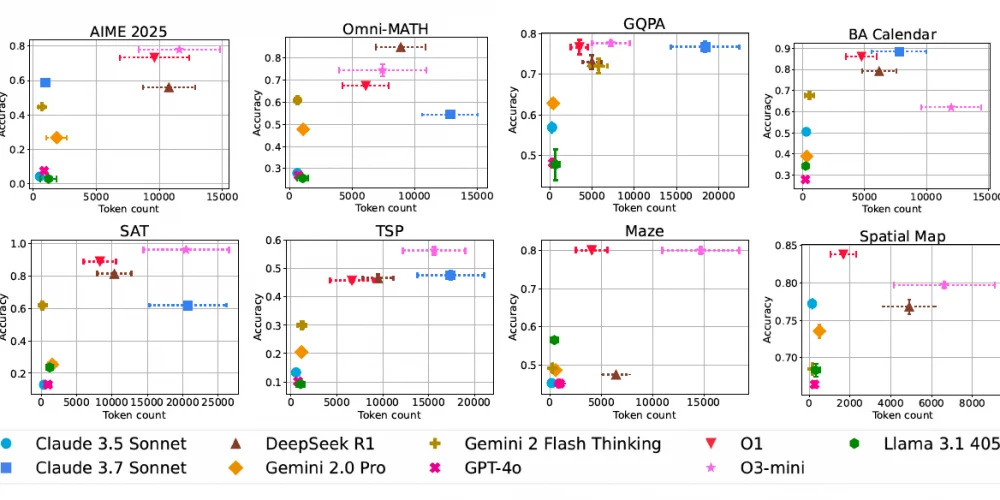
Исследователи протестировали три различных подхода к масштабированию: стандартную цепочку рассуждений (Chain-of-Thought), параллельное масштабирование с множественными ответами и последовательное масштабирование с итеративным улучшением результатов. Тестирование проводилось на восьми сложных наборах данных, охватывающих математику, календарное планирование, NP-сложные задачи, навигацию и пространственное мышление.
Ключевым открытием стало выявление «разрыва между обычными моделями и моделями рассуждений». Этот показатель сравнивает лучшие возможные результаты традиционной модели с средней производительностью модели рассуждений, что позволяет оценить потенциальный выигрыш от улучшения методов обучения и верификации.
Исследование имеет огромное значение для бизнеса: компании, внедряющие ИИ-системы, теперь смогут лучше понимать волатильность затрат и надежность моделей. Особенно важным оказался анализ того, как точность и использование токенов масштабируются с увеличением сложности задач — аспект, который до сих пор оставался малоизученным в контексте масштабирования во время выполнения задач.