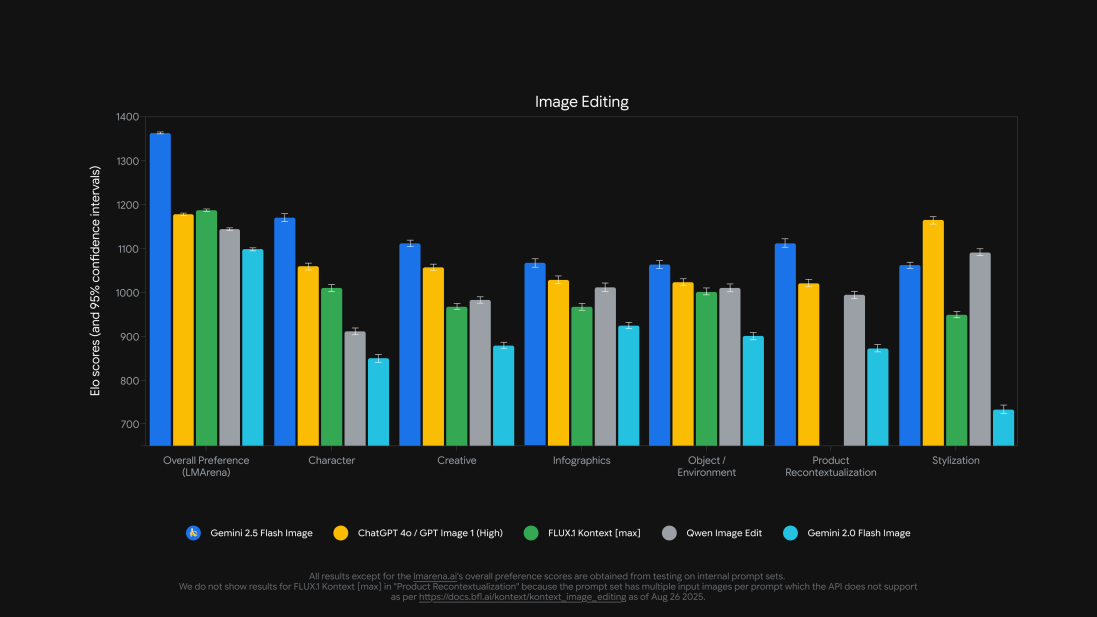
Google объявила о значительном обновлении визуальных возможностей своего чат-бота Gemini, интегрировав новую модель генерации и редактирования изображений Gemini 2.5 Flash Image. Развертывание технологии началось и охватит всех пользователей приложения Gemini, а также станет доступно разработчикам через Gemini API, Google AI Studio и платформу Vertex AI.
Архитектурные особенности новой модели обеспечивают прецизионное редактирование изображений на основе текстовых инструкций при сохранении высокой степени консистентности в отображении лиц, животных и других детализированных элементов – область, в которой конкурирующие решения демонстрируют системные ограничения.
Данный технологический прорыв решает фундаментальную проблему существующих инструментов, когда, например, запрос на изменение цвета одежды в ChatGPT или Grok от xAI часто приводит к деформации лиц или непреднамеренной модификации фона.
Примечательно, что до официального анонса модель функционировала в инкогнито-режиме на платформе краудсорсинговой оценки LMArena под псевдонимом “nano-banana”, где вызвала значительный резонанс в профессиональном сообществе благодаря превосходным результатам в сравнительных тестах.
Google подтвердила свое авторство данной разработки, уточнив, что это интегральный компонент флагманской модели Gemini 2.5 Flash AI.
“Мы существенно продвигаем визуальное качество и способность модели следовать инструкциям,” – прокомментировала Николь Брихтова, руководитель направления визуальных генеративных моделей в Google DeepMind. “Это обновление значительно улучшает плавность редактирования, и результаты работы модели применимы для широкого спектра пользовательских сценариев,” – добавила она.
