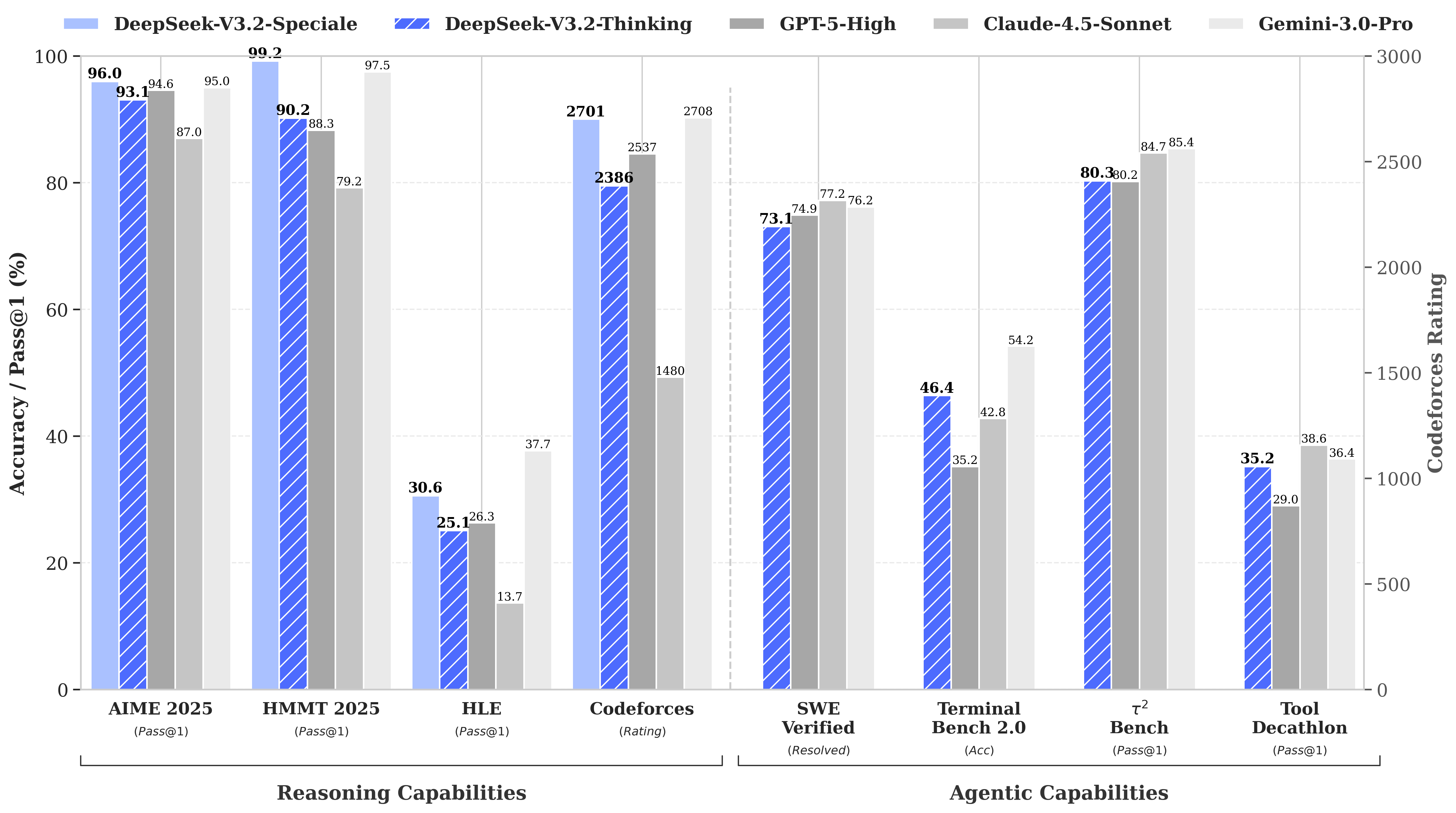
Китайский стартап DeepSeek представил модели нового поколения - DeepSeek-V3.2 и DeepSeek-V3.2-Speciale, созданные специально для продвинутого reasoning и работы в агентных системах. По производительности V3.2 демонстрирует впечатляющий баланс скорости и качества, выходя на уровень GPT-5. Однако настоящей звездой релиза стала версия Speciale, которая показывает топовый reasoning и прямо конкурирует с Gemini-3.0-Pro.
Более того, Speciale уверенно лидирует на престижных олимпиадах - IMO, CMO и ICPC. V3.2-Speciale стала первой опенсорсной моделью, завоевавшей золото на топовых олимпиадах. Модель триумфально получила золотые медали на IMO 2025, CMO 2025, IOI 2025 и ICPC WF 2025.
DeepSeek-V3.2 позиционируется как официальный преемник экспериментальной версии V3.2-Exp. Модель уже доступна пользователям через мобильное приложение, веб-сайт и API. Её младший брат - DeepSeek-V3.2-Speciale - представляет собой улучшенную версию с акцентом на продвинутое многошаговое рассуждение, пока доступную исключительно через API.
Обе модели делают ставку на глубокие цепочки рассуждений и поведение, заточенное под агентные сценарии: планирование задач, решение сложных проблем, построение комплексных выводов и работу со структурированными данными.
Технологический прорыв стал возможен благодаря новому подходу к обучению агентов. Команда DeepSeek синтезировала масштабные тренировочные данные для более чем 1800 различных сред и 85 тысяч сложных инструкций. V3.2 стала первой моделью компании, у которой мышление встроено непосредственно в процесс использования инструментов (tool-use).
Впрочем, у медали есть и обратная сторона. DeepSeek-V3.2-Speciale отличается огромными затратами на вычисления во время работы (test-time compute). Модель совершенно не экономит токены, что делает инференс достаточно дорогостоящим. Тем не менее, результаты говорят сами за себя - опенсорсные модели впервые достигли олимпиадного уровня мирового класса.
