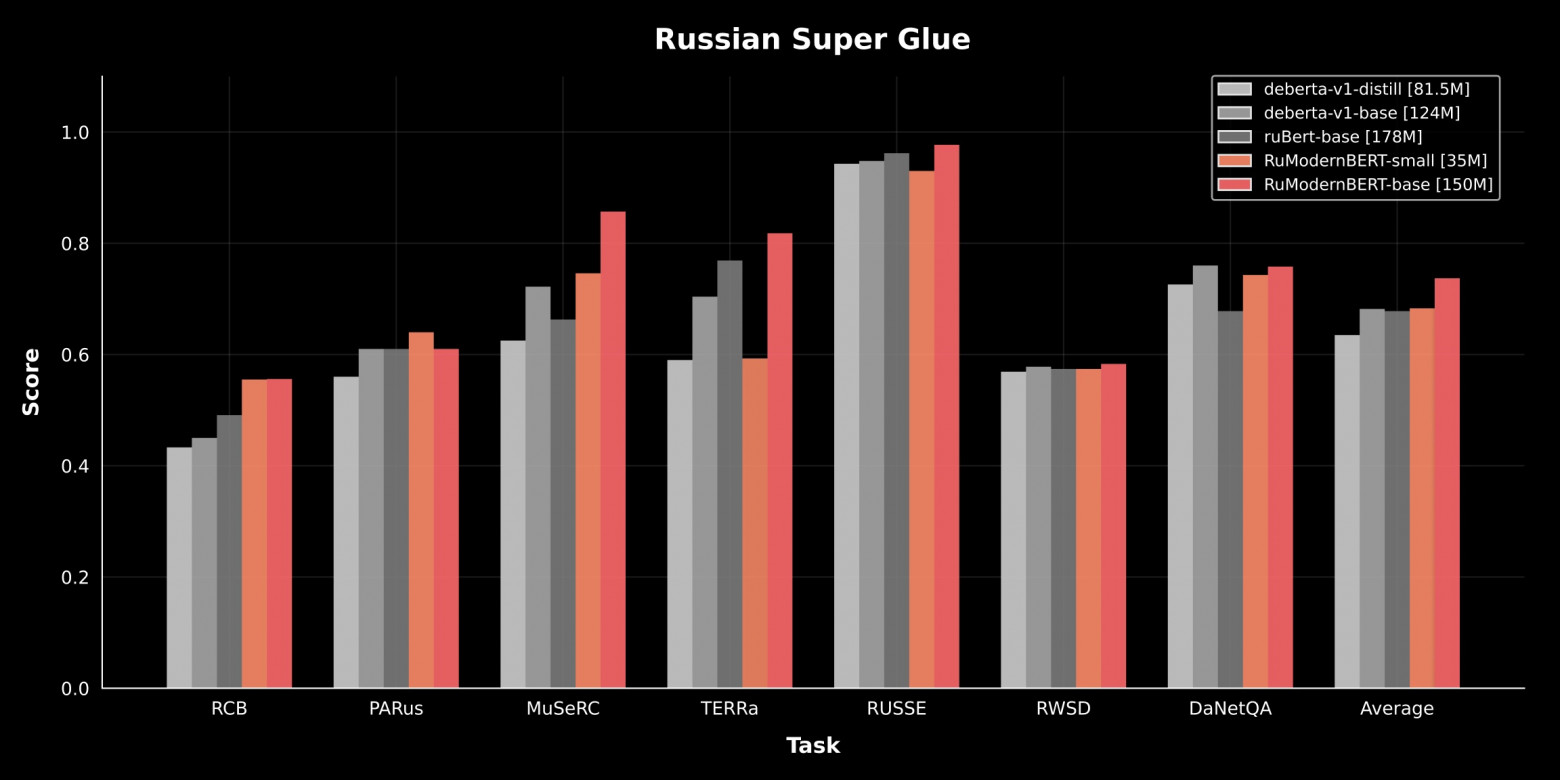
VK опубликовала языковую модель RuModernBERT, предназначенную для обработки разговорного русского языка. Ключевая особенность разработки - способность анализировать длинные тексты целиком, без необходимости разбиения на фрагменты. Модель функционирует локально, без использования внешних API, что снижает нагрузку на инфраструктуру.
RuModernBERT ориентирована на решение широкого спектра задач текстовой обработки. Среди приоритетных направлений применения - извлечение информации, анализ тональности, а также поиск и ранжирование в различных сервисах и приложениях.
Обучение модели проводилось на масштабном корпусе из 2 триллионов токенов, включающем данные на русском, английском языках и программном коде. Контекстное окно расширено до 8192 токенов, что существенно превышает параметры многих аналогичных решений.
Разнообразие обучающей выборки, включавшей книги, статьи, посты и комментарии в соцсетях, обеспечивает адаптивность к современным языковым конструкциям и разговорной речи.
Технический релиз предусматривает две версии модели: полноразмерную с 150 миллионами параметров и облегченную с 35 миллионами параметров. Это дает инженерам возможность выбора оптимальной конфигурации в зависимости от требований проекта и доступных вычислительных ресурсов.
Архитектурные усовершенствования обеспечивают значительный прирост производительности. Процессы обучения и развертывания модели выполняются на 10-20% быстрее по сравнению с предыдущими версиями. Обработка длинных текстов ускорена в 2-3 раза относительно базовой модели ModernBERT.
