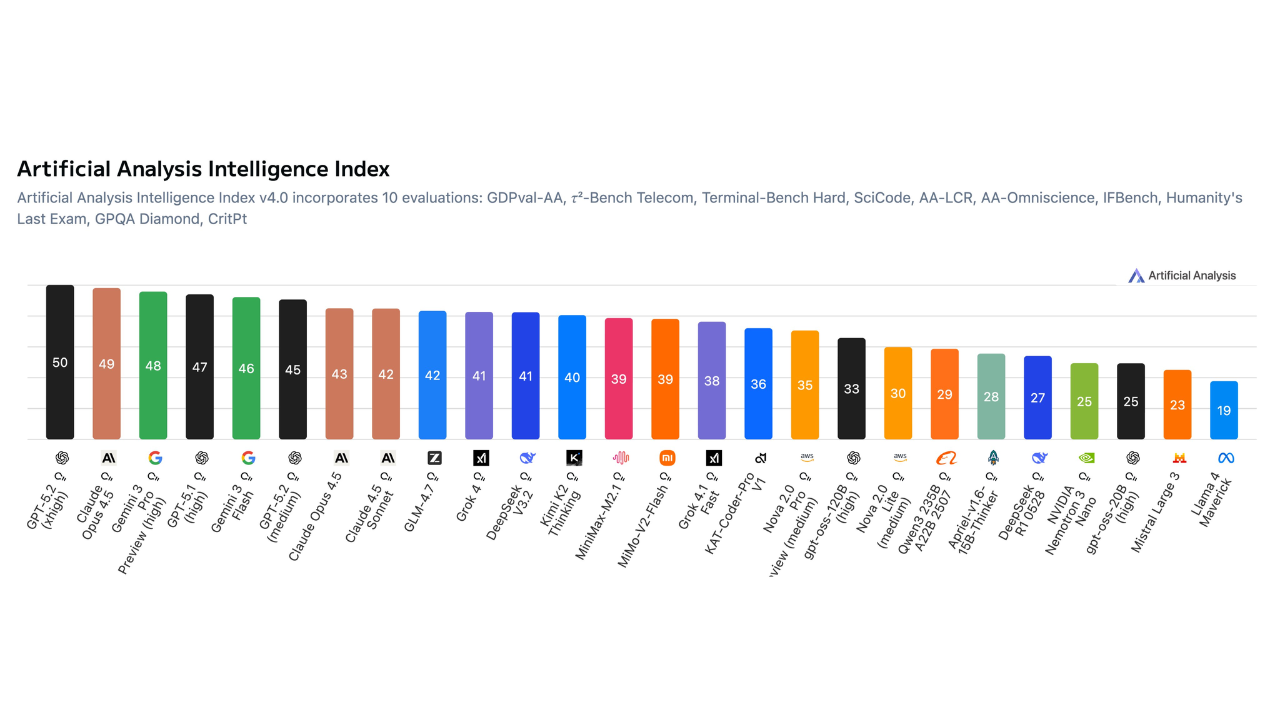
Artificial Analysis представила обновленный рейтинг ИИ-систем Intelligence Index 4.0. Результаты показали неожиданную картину - разница между тремя ведущими моделями практически исчезла.
По итогам измерений на первой строчке оказалась GPT-5.2 X-High от OpenAI. Однако её преимущество над Claude Opus 4.5 и Gemini 3 Pro настолько мало, что находится в пределах статистической ошибки. Фактически можно говорить о троевластии на рынке больших языковых моделей.
Авторы исследования кардинально пересмотрели подход к оценке. Старые бенчмарки потеряли актуальность. Разработчики моделей годами оптимизировали свои системы именно под эти тесты. В результате показатели росли, но это не всегда отражало реальные возможности ИИ.
Новая версия индекса построена на принципиально другой базе. Вместо известных AIME 2025 и MMLU-Pro появились три свежих набора заданий. Каждый проверяет отдельный аспект интеллекта.
Тест AA-Omniscience измеряет объем знаний и способность избегать галлюцинаций. Модели должны отличать факты от вымысла и признавать границы своей компетенции.
GDPval-AA оценивает применимость в реальной работе. Набор охватывает 44 профессиональные сферы - от банковского дела до клинической практики. Здесь важна не эрудиция, а умение решать прикладные задачи.
CritPt сфокусирован на научном подходе. Модели работают с физическими явлениями и инженерными расчетами. Проверяется логика рассуждений и точность выводов.
Общая оценка формируется из четырех блоков: агентные способности, написание кода, научное мышление и универсальные навыки. Это дает многомерный портрет каждой системы.
Ужесточение критериев привело к драматическому падению баллов. Если в предыдущих версиях лидеры получали более 70 пунктов, то сейчас планка опустилась до 50. Это не регресс технологий, а возврат к адекватной шкале сложности.
Исследователи отмечают важный тренд. Модели перестали конкурировать по общему уровню. Теперь каждая имеет уникальный профиль компетенций. Одна сильнее в многошаговых агентных сценариях. Другая стабильнее при научных выкладках. Третья реже ошибается в фактах.
Это меняет саму логику выбора инструмента. Вместо вопроса “какая модель лучше” появляется вопрос “какая модель лучше для моей задачи”. Универсального чемпиона больше нет. Есть три равноценных варианта с разными сильными сторонами.
