Исследовательская команда Сбера представила на конференции ACL 2025 новую языковую модель GigaEmbeddings, предназначенную для улучшения поисковых систем и создания чат-ботов. Модель специально разработана для эффективной обработки русского языка с применением технологий искусственного интеллекта в бизнес-среде.
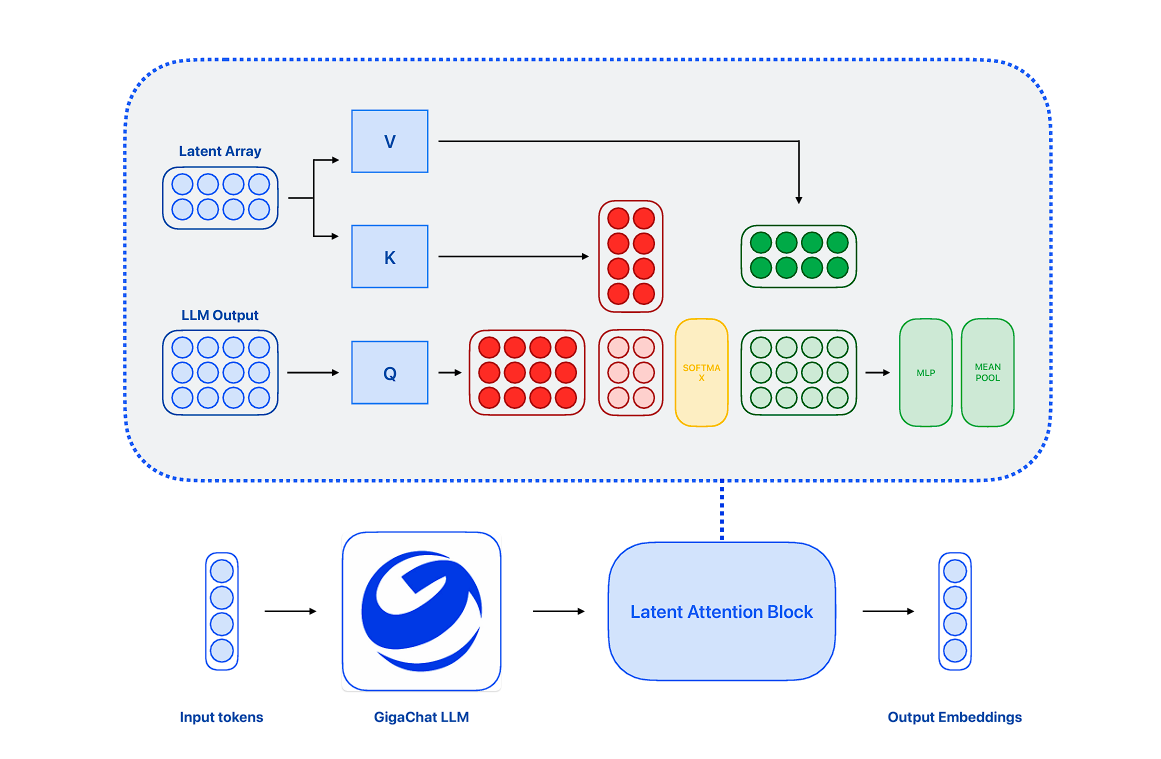
Техническую основу новой разработки составила модель GigaChat-3B, на базе которой был реализован трехэтапный процесс обучения. Обучение включало предварительную тренировку, точную настройку параметров и мультизадачное обучение.
В результате оптимизации архитектурных решений разработчикам удалось сократить количество параметров модели на 25% без ухудшения качественных показателей работы.
По информации Сбера, существовавшие ранее инструменты для работы с русским языком не удовлетворяли потребностям бизнеса.
Доступные решения либо требовали значительных вычислительных мощностей, либо показывали недостаточную эффективность при решении задач поиска, классификации и кластеризации текстов. GigaEmbeddings предлагает сбалансированное решение этих проблем.
Практическое применение модели охватывает несколько ключевых направлений. В сфере электронной коммерции GigaEmbeddings обеспечивает интеллектуальный поиск с улучшенным пониманием пользовательских запросов на маркетплейсах. Для корпоративных коммуникаций модель позволяет создавать чат-боты с расширенными возможностями на основе RAG-систем.
В банковском секторе и финтехе GigaEmbeddings эффективно анализирует обращения клиентов. Дополнительно модель применима для формирования персонализированных рекомендаций в медиа-проектах и розничной торговле.
